Download the English version
Natural language processing technologies are becoming ever-more accessible with the emergence of software as a service. This paper provides a comparison of several cloud services for natural language processing in four languages: English, French, Spanish and German. We consider four major cloud computing players: Amazon with Comprehend, Microsoft Azure with Text Analytics, Google Cloud with Natural Language and IBM Watson with Natural Language Understanding. Each offering is analyzed and rated based on context, ease of use, standard functionalities, application programming interface features, supported languages, quality of results, and price.
Ci-dessous : article de National Geographics, Why Do Many Reasonable People Doubt Science? support de ce comparatif.
Nous remercions National Geographics pour la fourniture du contenu de l’article en 4 langues : anglais, français, espagnol et allemand.
 La lecture par des machines de contenus écrits par des humains est un domaine de l’intelligence artificielle appelé traitement de la langue naturelle. Ce champ de recherche à la croisée de la linguistique, de la sémantique et de l’apprentissage automatique a atteint un niveau qualitatif suffisant pour quitter les laboratoires et investir l’économie productive. Des entreprises de tous secteurs d’activité utilisent aujourd’hui ces technologies pour valoriser leurs données et augmenter leur productivité. Des cas d’usage fréquents sont l’indexation et de la catégorisation de contenus, la fouille de données, l’analyse de retours consommateur, la veille informationnelle.La mise en œuvre des technologies de langue naturelle est de plus en plus aisée, notamment via les offres Software As A Service (SaaS). Il n’est pas nécessaire d’installer des logiciels complexes. Pour la récupération d’informations standardisées telles que entités reconnues dans le contenu, analyse du sentiment du contenu, mots-clés, il n’y a pas d’expertise à avoir dans ce domaine. Il suffit de fournir le contenu à une interface de programmation (API) publique et de récupérer le résultat. La tarification à l’usage limite l’investissement initial du projet.Pour ce comparatif, nous nous sommes intéressés aux offres SaaS d’acteurs majeurs du cloud computing : Amazon Comprehend, Microsoft Azure Text Analytics, Google Cloud Natural Language et IBM Watson Natural Language Understanding.
La lecture par des machines de contenus écrits par des humains est un domaine de l’intelligence artificielle appelé traitement de la langue naturelle. Ce champ de recherche à la croisée de la linguistique, de la sémantique et de l’apprentissage automatique a atteint un niveau qualitatif suffisant pour quitter les laboratoires et investir l’économie productive. Des entreprises de tous secteurs d’activité utilisent aujourd’hui ces technologies pour valoriser leurs données et augmenter leur productivité. Des cas d’usage fréquents sont l’indexation et de la catégorisation de contenus, la fouille de données, l’analyse de retours consommateur, la veille informationnelle.La mise en œuvre des technologies de langue naturelle est de plus en plus aisée, notamment via les offres Software As A Service (SaaS). Il n’est pas nécessaire d’installer des logiciels complexes. Pour la récupération d’informations standardisées telles que entités reconnues dans le contenu, analyse du sentiment du contenu, mots-clés, il n’y a pas d’expertise à avoir dans ce domaine. Il suffit de fournir le contenu à une interface de programmation (API) publique et de récupérer le résultat. La tarification à l’usage limite l’investissement initial du projet.Pour ce comparatif, nous nous sommes intéressés aux offres SaaS d’acteurs majeurs du cloud computing : Amazon Comprehend, Microsoft Azure Text Analytics, Google Cloud Natural Language et IBM Watson Natural Language Understanding.
Méthodologie
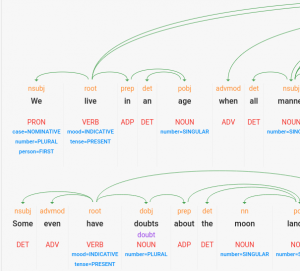
Nous décrivons chaque offre suivant plusieurs axes d’analyse : contexte, facilité d’utilisation, fonctionnalités standard, caractéristiques de l’API, langues supportées, qualité des résultats, prix.
Nous nous intéressons à l’analyse de contenu standard qui comprend les tâches suivantes, avec des variantes suivant l’offre :
– Détection de la langue du contenu
– Détection des entités nommées et des concepts
– Détection des mots-clés
– Détection d’informations morpho-syntaxiques : unités lexicales (tokens), catégorie grammaticale (part of speech), lemme, relation entre syntagmes
Certains fournisseurs proposent la création de modèles spécifiques clients. Nous n’avons pas testé ces offres mais nous indiquons quand elles existent.
Pour évaluer les offres, nous traitons le début (paragraphes jusqu’à 5000 caractères) d’un article de National Geographics Why Do Many Reasonable People Doubt Science ? par Joel Achenbach et Richard Barnes, publié en Mars 2015. Nous le traitons en anglais, espagnol, français et allemand. Nous utilisons l’interface graphique proposée dans chaque offre, souvent cette interface relève plus de la démonstration que d’un environnement de travail.
Le lien vers l’article espagnol ne correspond pas au début de l’article traité ici. L’article en français n’est pas disponible sur Internet. Les versions publiées dans les différentes langues ne sont pas des traductions mot à mot mais tout de même assez fidèles. À cause de la coupure au paragraphe précédent 5000 caractères, l’article en anglais contient parfois 1 ou 2 paragraphes en plus de certaines autres langues (paragraphes sur Ebola ou le journal Science).

Les résultats que nous obtenons sur un exemple donnent une ‘idée’ des résultats que l’on peut obtenir. Il s’agit de résultats qualitatifs et non de résultats scientifiques et définitifs qui nécessitent le test des différentes offres sur des corpus de documents bien définis et le calcul de métriques standard (précision, rappel, score F1.
Le document que nous utilisons est un article de presse. A ce titre, il possède certaines qualités que l’on ne retrouve pas forcément sur d’autres types de contenus :
– Phrases bien construites, correctes syntaxiquement
– Correspond au type de document qui est utilisé pour entraîner les modèles linguistiques et d’extraction d’information, donc normalement donne de meilleurs résultats que d’autres types de documents
– Phrases parfois complexes syntaxiquement, longues avec des subordonnées ou des inserts (c’est le cas ici)
– Dans cet article, précisément, des caractères moins standard (guillemets ouvrantes, tirets non standard) et parfois une casse plus complexe (titres avec tous les mots avec la première lettre en majuscule, ou certains mots en majuscule dans l’article en français)
Pour comparer le coût d’utilisation, nous avons créé deux cas d’usage simples. Le premier cas correspond à l’analyse du contenu des médias sociaux, des réclamations consommateurs, commentaires concernant les produits ou les services. Nous considérons ainsi 10 000 documents courts par mois, de 256 octets en moyenne, par mois. Le deuxième cas correspond plutôt à l’analyse des documents plus volumineux, articles de presse, comptes rendus ou documents contractuels. Ses principales caractéristiques sont 10 000 documents plus longs par mois, de 3 000 octets en moyenne, correspondant approximativement à une page A4.
Dans les deux cas, les documents sont analysés au fil de l’eau, avec un appel au service par document, sans aucun traitement de regroupement ou découpage ayant pour l’objet l’optimisation des coûts. Dans les deux cas, on détecte la même chose – la langue, les entités nommées, le sentiment et les mots-clés.
Amazon Comprehend
Amazon Web Services (AWS) s’est lancé relativement récemment (fin 2017) dans l’analyse en langue naturelle avec Amazon Comprehend. C’est un des nombreux services proposés par le géant du cloud computing. Un service dédié à l’analyse de contenu médical, Comprehend Medical, a été lancé fin 2018 ; nous ne testons pas ce service.
Comprehend peut traiter des contenus en anglais, français, espagnol, italien, portugais, allemand sur l’ensemble des opérations : langue, entités nommées et concepts, mots-clés, sentiment et syntaxe. Il est possible de créer des modèles spécifiques d’extraction et de classification avec Comprehend Custom ; nous ne testons pas ce service. Notons que l’interface graphique et l’API permettent de lancer des tâches de traitement de manière asynchrone. Aussi, l’API peut chercher un document directement dans un stockage S3 (stockage d’objets d’AWS).
L’utilisation du service est assez simple puisqu’il suffit de créer un compte AWS. Il n’y a qu’un seul forfait avec une première tranche gratuite jusqu’à 50 000 unités. 1 unité correspond à 100 caractères et il y a un minimum de 3 unités par requête. Ensuite et jusqu’à 10 millions d’unités, l’unité coûte $0.0001. En considérant uniquement la première tranche payante, traiter 10 000 messages courts de 256 octets revient à 10,7€. Le traitement de 10 000 pages A4 (environ 3 000 caractères) coûte 107,1€.
La documentation de Comprehend est claire mais uniquement disponible en anglais. L’interface graphique et l’API limitent la taille des contenus à 5000 caractères par appel, ce qui est trop peu et oblige à l’utilisateur à segmenter ses contenus. Seul du texte brut peut être envoyé. Il faudra donc pré-extraire le texte de ses contenus (XML, HTML, PDF, Word, etc.). L’API est HTTP REST. Des librairies clientes pour cette API sont disponibles dans les langages courants (Python, .NET, Java, Javascript). Sur l’aspect confidentialité, vos données peuvent être utilisées par AWS pour améliorer le service Comprehend.
Une fois connecté à AWS, il faut chercher le service Comprehend. Il est nécessaire de choisir la région AWS où l’on souhaite effectuer le traitement. Toutes les régions ne sont pas disponibles. On arrive sur une console où on peut traiter un document de test. L’interface graphique de test se veut plus qu’une interface de démonstration et est certainement plus utilisable que les interfaces de ‘démo’ de certains services concurrents. L’interface présente notamment un surlignage des occurrences de résultats et l’affichage de la réponse de l’API. Malgré tout, l’interface a quelques bugs : il est parfois nécessaire de cliquer sur l’écran pour déclencher l’affichage des résultats et il n’y pas de barre de défilement vertical affichée au niveau du texte. Nous avons rencontré un message d’erreur ‘taille dépassée’ alors que la console indique moins de 5000 caractères.
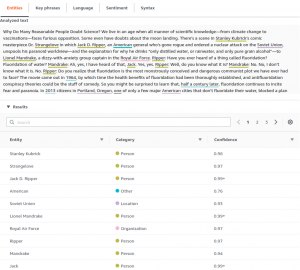
Voici nos résultats sur l’analyse du début (5000 caractères) de l’article de National Geographics, Why Do Many Reasonable People Doubt Science ? dans les 4 langues : anglais, français, espagnol, allemand. Le temps de traitement pour l’ensemble des traitements est rapide (1 seconde) quelle que soit la langue. La détection de langue fonctionne correctement. Les entités nommées sont classées en personne, lieu, organisation, produit, date, événement, quantité, titre et autre. Un score de confiance est fourni. Par contre il n’y a pas de détection de concepts, on reste donc sur de la détection pure d’entités nommées (noms propres). Surtout il n’y a pas de liens vers un objet d’un graphe de connaissance (typiquement une URI de Wikipédia ou DBPedia) ce qui est dommage. On saura que ‘Stanley Kubrick’ est une personne mais on ne saura pas qui il est. Les services concurrents proposent souvent cette fonctionnalité. Pour les entités nommées, les résultats en anglais sont très bons, on pourrait éventuellement discuter de quelques cas-limites. En français, les résultats sont tout à fait bons. Une erreur sur ‘d’Ebola’ = organisation mais avec une confiance faible. Beaucoup de quantités sont détectées, peut-être trop (ex : ‘rares grandes villes’). ‘Jack D. Ripper’ est scindé en 2 entités Personne différentes ‘Jack D.’ et ‘Ripper’ (ce n’est pas le cas en anglais). Des concepts sont parfois détectés en tant qu’entité de type Autre (ex : fluoride, pandémie). En espagnol, les résultats sont très bons. ‘cancer’ est détecté en tant que entité de type Autre. En allemand, les résultats sont bons. Il y a quelques erreurs, 2 mauvaises détections mais avec une confiance moyenne (0.6) : ‘Air-Force-General’ comme Produit et ‘Mandrake’ comme Organisation. Une occurrence de ‘Ripper’ n’a pas été détectée. Il y a un peu trop de quantités détectées, par exemple : ‘ohne Sorge’ (sans souci), ‘alle’ (tous), ‘viele’ (beaucoup) et des concepts sont parfois détectés comme entités de type Autre, par exemple ‘Fluorid’ (fluorure), ‘Ebola’.
La détection des mots-clés dans Comprehend consiste d’après la documentation à trouver tous les groupes nominaux d’un contenu et effectivement les résultats montrent que cet objectif est atteint. Il y a un indice de confiance, mais pas de score de pertinence qui permettrait de trier (et filtrer) les (nombreux) mots-clés trouvés. Dans ces conditions, je trouve que l’utilité de cette extraction est un peu limitée. En anglais, français et espagnol, elle fait ce qu’on lui a demandé. Cela conduit parfois à des extractions qui ne semblent pas très pertinentes. Ex : ‘principle’ dans ‘in principle’, ‘nous’, ‘tel’, ‘aumento’. En allemand, on note des problème de tokenisation et de séparation de phrases ‘der Zweifler Die Skepsis gegenüber der Wissenschaft’, ‘doch.“ Ripper’.
Pour l’analyse de sentiments, il n’y a pas de consensus sur les métriques standard décrivant un résultat d’analyse de sentiments et chaque offre propose sa manière de représenter ce type de résultat. Il faudra étudier chaque offre pour bien la comprendre. Malgré tout, les valeurs numériques associées au résultat semblent parfois obscurs. De plus, l’analyse de sentiments est un sujet subjectif, qui n’est peut-être pas très adapté à un article de presse. L’article de presse de National Geographics que nous utilisons est-il neutre ou négatif ? Le ton est plutôt factuel et neutre mais on parle de choses clairement négatives. Amazon Comprehend indique un sentiment neutre pour l’anglais, le français, l’espagnol. Pour l’espagnol, le sentiment est neutre à 0.7 et négatif à 0.2.
L’analyse syntaxique donne uniquement les unités lexicales et leur catégorie grammaticale, avec un indice de confiance. D’autres services concurrents proposent plus d’information. En anglais, on note des problèmes de tokenisation sur des caractères de ponctuation Unicode probablement moins habituels (apostrophes, guillemets, tirets). Peut-être un défaut de normalisation de caractères à corriger. Ex d’unités lexicales erronées : ‘knowledge—from’, ‘There’s’. Cela entraîne des erreurs de catégories grammaticales sur ces unités lexicales.
Sinon le résultat est de bonne qualité sur les catégories qui seront probablement utiles à l’utilisateur, à savoir nom, adjectif, verbe. Pour d’autres catégories plus annexes, le résultat est parfois sujet à discussion. Ex : ‘Why’ est classé comme adverbe. Pour le français, l’analyseur est trompé par la casse un peu exotique des premières phrases : dans ‘AUX ÉTATS-UNIS, Le scepticisme EST À SON COMBLE’, ‘AUX’ est classé comme Nom propre ainsi que ‘EST’ et ‘SON’. Des problèmes liés à la ponctuation comme en anglais. Ex : ‘l’évolution’ est une seule unité lexicale. La détection est sinon de bonne qualité. ‘Pourquoi’ est classé comme adverbe. ‘Et’ n’a pas de catégorie grammaticale. Pour l’espagnol, de manière identique, la casse de ‘INCREDULIDAD’ le pousse à le classer comme Nom propre. ‘y’ ou ‘que’ n’ont pas de catégorie. Il y a quelques erreurs sur les catégories les plus utiles. Ex : pour la phrase ‘El agua fluorada causa cancer’, ‘fluorada’ est classé comme verbe (indice de confiance moyen à 0.49) et ‘causa’ est classé comme Nom avec une confiance haute de 0.91 et ‘cáncer’ est classé comme adjectif (0.88). ‘¿Teléfono’ est une seule unité lexicale classée comme Nom propre. ‘Ripper’ est classé comme verbe. Sinon les résultats sont bons. En allemand, ‘Die Skepsis gegenüber der Wissenschaft’ (le scepticisme contre la science) donne ‘Die’ et ‘Skepsis’ classés comme Nom propres. Peut-être un problème de segmentation avec les paragraphes, la phrase précédente (le titre) n’a pas de point final mais est séparé par 2 retours chariots. ‘„Haben’ et ‘„Äh’, classés comme des Noms propres sont peut-être victimes des caractères Unicode inhabituels. Une erreur sur ‘diese’ classé comme Pronom dans ‘diese Szene’. Hormis ces problèmes, la détection en allemand est de bonne qualité.
La tarification d’offre est relativement simple et elle semble bien adaptée au traitement d’un grand nombre des contenus courts.
Azure Cognitive Services Text Analytics

Cognitive Services Text Analytics est l’offre de Microsoft depuis 2016 au sein sa plateforme cloud Azure.
Text Analytics peut détecter jusqu’à 120 langues et présente un support, variable et souvent en pré-version, de 22 langues pour le sentiment, les mots-clés et les entités nommées et concepts (langues européennes, arabe, chinois simplifié, japonais, coréen, turc). En version définitive, les entités nommées sont disponibles pour l’anglais et l’espagnol ; l’analyse de sentiments est disponible en anglais, français, espagnol et portugais. Le français propose donc de l’analyse de sentiments et les mots-clés. Il n’est pas possible de créer des modèles linguistiques ou de classification personnalisée avec Text Analytics. On peut cependant développer ses propres modèles d’apprentissage automatique avec le module Microsoft ML ou des modèles orientés chatbot avec le module Language Understanding. Text Analytics peut être utilisé en tant que service cloud ou lancé dans un container Docker. Dans ce dernier cas, le container Docker peut être déployé sur un hôte quelconque, qu’il soit local, dans le cloud Azure ou chez un autre fournisseur de cloud. La tarification est identique dans les 2 modèles ; par contre le container permet de traiter les contenus localement et d’avoir la garantie qu’ils ne sont pas communiqués à Azure. Cependant le container est limité à la détection de langue, de sentiment et les mots-clés.
Un compte Azure est nécessaire pour utiliser Text Analytics. Il faut ensuite chercher le service Text Analytics, ce qui n’est pas simple car le service est caché dans un onglet “Plus” du répertoire Cognitive Services. Il est nécessaire de choisir la région où l’on souhaite effectuer le traitement. Toutes les régions ne sont pas disponibles.
Plusieurs forfaits sont disponibles, la tarification est assez complexe. Un forfait gratuit est limité à 5000 transactions par mois. Un forfait Standard S sans base fixe à 2$ les 1000 enregistrements de texte (portions de 1000 caractères) jusqu’à 500 000 enregistrements puis dégressif. Des forfaits S0 à S4 avec une base fixe de 75$ à 5000$ par mois avec une quantité de transactions incluses par mois croissante, de 25 000 à 10 millions. Au-delà, les transactions sont facturées. Une transaction correspond à une opération sur un document. Avec le forfait S, traiter 10 000 messages courts de 256 octets revient à 67,5€ et le traitement de 10 000 pages A4 (environ 3 000 caractères) coûte 202,4€.
La documentation de Text Analytics fournit les informations nécessaires mais semble un peu moins claire que dans d’autres offres. Elle est en français mais via une traduction automatique de l’anglais et certaines phrases sont obscures. La liste des langues indique ‘anglais’ là l’on parle du français, ce qui est pour le moins trompeur. Certaines ressources ne sont disponibles qu’en anglais (API, forum, base de connaissance). L’interface graphique et l’API limitent la taille des contenus à 5120 caractères par document, ce qui est trop peu et oblige à l’utilisateur à segmenter ses contenus. Seul du texte brut UTF-8 peut être envoyé. Il faudra donc pré-extraire le texte de ses contenus (XML, HTML, PDF, Word, etc.). L’API est HTTP REST. Des librairies clientes pour cette API sont disponibles dans les langages courants (Python, .NET, Java, Javascript). Sur l’aspect confidentialité, vos données peuvent être utilisées par Microsoft pour améliorer le service Text Analytics, sauf dans le cas d’un container Docker.
Text Analytics ne fournit pas de console graphique d’analyse de documents en tant que telle mais uniquement une interface de démonstration, accessible sans compte Azure. Cette interface de démonstration propose un surlignage des entités détectées mais pas des mots-clés. La sortie JSON de l’API est visible.
Voici nos résultats sur l’analyse du début (5000 caractères) de l’article de National Geographics, Why Do Many Reasonable People Doubt Science ? dans les 4 langues : anglais, français, espagnol, allemand. Le temps de traitement pour l’ensemble des traitements est rapide (1 seconde) quelle que soit la langue. La détection de langue fonctionne correctement. Nous testons les entités nommées avec l’interface de démonstration et l’interface ainsi que la sortie JSON ne donnent pas le type d’entité. L’information indiquée est l’URI Wikipédia et l’ID Bing associées à l’entité détectée. Il n’y a pas de score de confiance ou de pertinence. La documentation indique que le type d’entité est disponible avec la version 2.1 de l’API. Cette version n’a pas dû être branchée sur l’interface de démonstration. Les entités sont alors classées en Personne, Lieu, Organisation, Quantité, Date, URL et Email. La détection d’entités n’est pas disponible en français et en allemand. En anglais, la qualité de la détection n’est pas bonne. Des concepts ou entités nommées sont agressivement plaquées sur le contenu sans réelle vérification du contexte. Ainsi ‘Do Many’ est attribué à la ville de Many en Louisiane, ‘Ah’ à Histoire alternative, ‘No’ à Norway respectivement dans : ‘Why Do Many People’, ‘Ah, yes’, ‘No virus’. Un autre exemple sur les concepts : ‘attack on the Soviet Union’ (dans ‘nuclear attack on …’) est attribué à Opération Barbarossa (événement de la 2e Guerre Mondiale). En espagnol, les résultats sont meilleurs qu’en anglais et limités aux entités nommées. Pas de concepts détectés ici contrairement à l’anglais. Les entités telles que Lune, Moscou, Stanley Kubrick sont détectées correctement et attribuées à la bonne ressource Wikipédia. Il reste cependant quelques erreurs importantes comme ‘Sí’ (oui) ou ‘No’ (non) détecté comme Système International de Mesures ou Théâtre Japonais No. ‘Jack D. Ripper’ et ‘Lionel Mandrake’ ne sont pas détectés.
L’extraction de mots-clés par Text Analytics vise, comme le service d’Amazon, à extraire les groupes nominaux des phrases du contenu. Il n’y a pas de score de confiance ou de pertinence. La FAQ de la documentation indique que les mots-clés sont triés par ordre d’importance décroissante. Cette information importante n’est pas présente ailleurs dans la documentation. En anglais, français, espagnol et allemand, les résultats sont conformes à l’objectif fixés. Beaucoup d’expressions sont extraites mais le tri permet de garder les éléments les plus significatifs. A cet égard, on retrouve dans les premiers éléments des expressions représentatives de l’article comme ‘scepticisme’, ‘consensus scientifique’. Parfois, les éléments extraits peuvent être moins pertinents, ex en français ‘forts’ dans ‘forts de leur expérience’. En allemand, un problème de catégorie grammaticale peut-être car le verbe ‘glauben’ est extrait.
L’analyse de sentiment renvoie un score entre 0 (négatif) et 1 (positif). L’article anglais reçoit un score très négatif (13%) alors que les versions française, espagnole et allemand reçoivent un score proche du neutre (entre 49% et 53%).
L’analyse syntaxique n’est pas disponible.
L’offre est financièrement assez simple, un peu plus onéreuse que celle d’Amazon. Sa principale limitation c’est l’impossibilité de l’adapter au spécifique du métier de l’usager. Donc, elle est probablement très intéressante pour traiter les contenus généraliste – type articles de presse – surtout en anglais.
Google Cloud Natural Language
Google Cloud est une plateforme de cloud computing complète. Parmi les services proposés, Natural Language permet l’analyse de contenus textuels depuis mi 2016.
Natural Language gère les contenus en anglais, français, espagnol, italien, portugais, allemand, russe, chinois simplifié et traditionnel, japonais, coréen sur ces opérations : entités nommées et concepts, sentiment et syntaxe. Il n’y a pas de détection de langue en tant que telle mais la langue est détectée et renvoyée dans la plupart des opérations. Il n’y a pas de détection de mots-clés a contrario des offres concurrentes. La classification de contenu selon une taxonomie Google est possible en anglais et l’analyse de sentiment par entité est disponible en anglais et japonais. Il est possible de créer des modèles spécifiques d’extraction et de classification avec AutoML (en version Bêta) ; nous ne testons pas ce service. Il n’y a pas de notion de jobs de traitement ou de traitement asynchrone. Aussi, l’API peut chercher un document directement dans un stockage Google Cloud Storage (stockage d’objets de Google Cloud).
Un compte Google Cloud est nécessaire pour utiliser Natural Language. Il n’y a qu’un seul forfait avec une première tranche gratuite jusqu’à 5 000 unités par mois. 1 unité correspond à 1000 caractères pour une opération. Ensuite et jusqu’à 1 million d’unités, l’unité coûte $0.001 pour les entités et les sentiments. L’analyse syntaxique vaut la moitié et l’analyse de sentiment des entités le double. Au-delà les tarifs sont dégressifs. La classification de contenu fonctionne sur une échelle différente. Elle est gratuite jusqu’à 30 000 unités par mois, puis $0.002 par unité jusqu’à 250 000 unités et des tarifs dégressifs ensuite. En considérant uniquement la première tranche payante, traiter 10 000 messages courts de 256 octets revient à 22,3€. Le traitement de 10 000 pages A4 (environ 3 000 caractères) coûte 67,0€.
La documentation en français est claire et agréable à utiliser. Il reste parfois quelques paragraphes en anglais dans une page en français et certaines ressources, comme la description des APIs, sont uniquement en anglais. Notons que token a été traduit en jeton, choix un peu malheureux pour parler d’unité lexicale.
L’API limite la taille des contenus à 1 Mo caractères par appel, ce qui est très convenable. D’autres limites (100 000 unités lexicales, 5000 entités) sont silencieuses, ne générant pas d’erreurs mais une absence de résultats au-delà de la limite. L’API accepte du texte brut ou du HTML. Il faudra donc pré-extraire le texte de ses contenus pour d’autres formats (XML, PDF, Word, etc.). L’API est HTTP REST. Des librairies clientes pour cette API sont disponibles dans les langages courants (Python, .NET, Java, JavaScript). Sur l’aspect confidentialité, la documentation indique qu’actuellement vos données ne peuvent pas être utilisées pour améliorer le service Natural Language mais peuvent être utilisées à des fins de débogage ou autres tests.
A notre connaissance, il n’y a pas de choix possible dans la localisation de l’exécution du traitement. Natural Language ne propose pas d’interface graphique de travail mais une interface de démonstration, accessible sans compte Google. Cette interface est plutôt bien faite avec un surlignage des détections d’entités et des représentations graphiques adaptées à chaque traitement, par exemple une visualisation graphique des dépendances syntaxiques. L’absence de barres de défilement verticales rend l’analyse de documents longs fastidieuse de même que l’absence d’information sur le surlignage, à part un numéro que l’on doit faire correspondre manuellement à l’entité correspondante. Le résultat JSON de l’API n’est pas accessible.
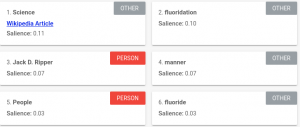
Voici nos résultats sur l’analyse du début (5000 caractères) de l’article de National Geographics, Why Do Many Reasonable People Doubt Science ? dans les 4 langues : anglais, français, espagnol, allemand. Le temps de traitement pour l’ensemble des traitements est rapide (1 seconde) quelle que soit la langue. La détection de langue fonctionne correctement. Natural Language détecte les entités nommées et les concepts et les classe en Personne, Lieu, Organisation, Événement, Autre, Inconnu, Travail artistique, Bien de consommation, Numéro de téléphone, Adresse, Date, Nombre, Prix. Natural Language ne renvoie pas de score de confiance sur la détection mais un score de pertinence par rapport au document ce qui est utile pour filtrer aux entités les plus intéressantes. Les entités et les concepts peuvent être reliées à une URI Wikipédia. En anglais, la détection des entités nommées est très bonne. Les entités sont correctement attribuées à leur URI Wikipédia lorsque cela est pertinent. Les concepts détectés sont nombreux cependant ils sont souvent classés en Autre et ont rarement une URI Wikipédia. On détecte uniquement les noms et pas les groupes nominaux ce qui différencie ce type de résultats par rapport à l’extraction de mots-clés des offres concurrentes. Le score de pertinence propose quelques concepts intéressants par rapport à l’article (ex : science) mais on ne voit pas d’éléments attendus comme ‘croyance’. On note quelques (rares) erreurs : ‘Lionel Mandrake’ est un Travail artistique. ‘Dr. Strangelove’ est séparé en 2 entités personnes différentes. En français, le score de pertinence retourne des concepts intéressants (ex science, scepticisme) mais parfois moins (guerre). La détection d’entités et de concepts est bonne mais un peu moins qu’en anglais. ‘marché’ est un verbe est non un concept. ‘lune’ n’est ni détectée comme un Lieu ni rapporté au concept Lune de Wikipédia. ‘farce’ est détecté comme un Bien de consommation (ambiguïté entre les 2 sens de farce). ‘Jack D. Ripper’ est séparé en 2 entités Personne. ‘Union Soviétique’ est détectée comme Lieu mais pas de lien sur Wikipédia (contrairement à l’anglais). ‘Science’ (on parle de la revue Science) est détecté comme Organisation et le lien Wikipédia pointe vers le concept science en tant que catégorie générale de connaissances. ‘fluoration’ est détecté comme Événement ou Autre. ‘organismes’ dans ‘organismes génétiquement modifiés’ est une Organisation. En espagnol, le score de pertinence donne ‘INCREDULIDAD’ ce qui est correct, le reste des détections à une pertinence proche de 0. La détection d’entités et de concepts est bonne mais il y a des erreurs. ‘RIPPER’ et ‘MANDRAKE’ sont détectés en Other. ‘Teléfono rojo’ (Téléphone rouge) est détecté en Bien de consommation. Moscú est détecté en Lieu mais pas relié à Wikipedia. ‘fuentes’ dans ‘fuentes de información’ (sources d’information) est détecté en Personne. ‘meme’ dans ‘meme de la cultura’ (mème de la culture populaire) est détecté en Personne. ‘Interstellar’ est détecté comme Lieu mais bien relié dans Wikipedia au film Interstellar. Apolo est détecté comme Personne. Il y a quelques entités sans type, sans information (ex : 1964). En allemand, la pertinence donne des entités intéressantes comme ‘Zweifler’ (sceptiques) et ‘Wissenschaft’ (science). La détection d’entités et de concepts est plutôt bonne mais il y a des erreurs, dont les entités nommées. ‘Ripper’ est détecté comme Bien de consommation ou Autre. ‘was’ (verbe être) est détecté comme Autre. ‘Stanley Kubricks’ est détecté comme Autre mais bien relié dans Wikipédia. ‘nein.’est détecté comme Autre. ‘einer’ est détecté comme Personne dans ‘einer der wenigen amerikanischen Großstädte’ (une des quelques villes américaines). ‘Frankenstein’ et ‘Frankenfood’ sont détectés comme Organisation. ‘Apollo’ est détecté comme Personne.
L’analyse de sentiments de Natural Language donne des résultats au niveau du document, de chaque phrase et au niveau de chaque entité (cette dernière fonctionnalité n’est pas présente dans l’interface de démonstration). Les sentiments sont exprimés par 2 métriques : un score entre -1 et 1, de sentiment négatif à positif, et une magnitude qui est la force du sentiment. En anglais, le sentiment est neutre avec un score de -0.1. En français, espagnol et allemand, l’analyse de sentiment n’est pas disponible.
L’analyseur syntaxique de Natural Language donne beaucoup d’informations : les catégories grammaticales, les informations morphologiques (lemme, genre, nombre, cas en allemand) et les dépendances entre unités lexicales. En anglais, l’analyseur syntaxique est de très bonne qualité. En français, on note quelques erreurs mais sinon la détection est bonne. ‘AUX’ est détecté ADP singulier alors que pluriel. ‘SON’ est détecté pronom alors que déterminant. L’analyseur est peut-être trompé par le casse dans ces 2 cas. ‘marché’ est détecté nom alors que verbe, d’où l’erreur sur la détection d’entités sûrement. ‘Jack D.’ : le point est pris pour une fin de phrase. En espagnol, la détection est de très bonne qualité. J’ai trouvé une erreur : ‘desmandado general’ (un général rebel) attribué à NOM ADJ alors que la bonne détection est ADJ NOM. L’analyse syntaxique en allemand est de bonne qualité. ‘Äh’ (ah) est détecté comme NOM. ‘Wissen’ est détecté comme NOM alors que c’est un verbe dans ‘Wissen Sie auch, was..’ (Savez-vous aussi que…). ‘nein.’ est détecté comme NOM alors qu’il est ailleurs détecté comme ADV ou X. ‘wussten’ est lemmatisé en ‘wussen’; le lemme correct est wissen). ‘seltsam’ est détecté en adverbe mais est plutôt un adjectif dans ‘Ist es nicht seltsam, dass..’ (N’est-il pas étrange que…).’In den USA, in Portland, Oregon, einer der wenigen amerikanischen Großstädte ohne fluoridiertes Trinkwasser, wurden im Jahr 2013 entsprechende Pläne der Stadtverwaltung abgeschmettert.’ (Aux États-Unis, à Portland, en Oregon, l’une des rares grandes villes américaines sans eau potable fluorée, le projet en ce sens de la municipalité a été rejeté en 2013. ): Dans cette phrase quelques imprécisions: ‘einer’ est détecté comme masculin nominatif alors que c’est un féminin datif relié à Stadt. La structure de la phrase est légèrement incorrecte. ‘ihrem’ est détecté comme PRONOM alors que déterminant (ihrem Wasser / votre eau).
Natural Language propose la catégorisation de l’article suivant un plan de classement propre. La fonctionnalité est disponible en anglais mais pas en français, espagnol ou allemand. Natural Language classe le contenu dans Health avec une pertinence de 0.52. Il ne s’agit pas vraiment du sujet principal de l’article même si on parle beaucoup de santé (fluore, Ebola).
Cette offre paraît intéressante surtout si elle est couplée avec l’utilisation de Google ML – le module machine learning.
IBM Watson Natural Language Understanding
Fondée en 2009, la société AlchemyAPI a développé une offre SaaS de traitement de langue naturelle. AlchemyAPI est achetée par IBM et intégrée à l’offre cloud IBM Watson en 2015. En 2016 son nom devient Natural Language Understanding.
Natural Language Understanding sait traiter des contenus en arabe, chinois simplifié, néerlandais, anglais, français, allemand, italien, japonais, coréen, portugais, russe, espagnol et suédois avec des niveaux de fonctionnalités très variables parmi la détection d’entités et concepts et les relations entre entités, la détection de mots-clés, l’analyse de sentiments et d’émotions, les rôles sémantiques (suivant un axe sujet-action-objet), la catégorisation du contenu dans un plan de classement propre et la syntaxe. Natural Language Understanding peut aussi extraire automatiquement des métadonnées pour un contenu HTML. La détection de relations entre entités est une fonctionnalité intéressante mais que nous n’avons pas pu tester car elle n’est pas présente dans l’interface de démonstration. Il est possible de créer des modèles spécifiques d’extraction et de classification avec IBM Watson Knowledge Studio ; nous ne testons pas ce service.
Un compte IBM Cloud permet d’accéder au service Natural Language Understanding. Il suffit de choisir la région de déploiement et le forfait. Les 6 centres proposés sont situés en Amérique du Nord, en Europe et pour la région Asie-Pacifique, au Japon et en Australie. La tarification du service est la suivante : un forfait gratuit limité à 30 000 éléments NLU par mois, un forfait standard à 0,003 $ par élément NLU par mois entre 0 et 250 000 éléments NLU puis tarif dégressif. Un élément NLU est un bloc de 10 000 caractères pour une fonction de l’API. Il est aussi possible de contacter IBM pour une tarification adaptée à des exigences spécifiques de sécurité des données. Avec le forfait standard, traiter 10 000 messages courts de 256 octets revient à 107,1€ et le traitement de 10 000 pages A4 (environ 3 000 caractères) est aussi à 107,1€.
La documentation de Natural Language Understanding est claire et en français. L’API est uniquement disponible en anglais par contre. L’API limite la taille des contenus à 50 000 caractères par appel, ce qui est assez raisonnable. L’utilisateur devra segmenter ses contenus longs. L’API traite du texte brut ou du HTML. Il faudra donc pré-extraire les autres types de contenus (XML, PDF, Word, etc.). L’API est HTTP REST. Des librairies clientes pour cette API sont disponibles dans les langages courants (Python, .NET, Java, JavaScript). Sur l’aspect confidentialité, l’API indique que par défaut les requêtes et résultats sont enregistrés par IBM et peuvent être utilisés pour améliorer le service. Indiquer l’en-tête X-Watson-Learning-Opt-Out dans la requête permet de refuser explicitement cette conservation.
L’interface graphique de Natural Language Understanding est une interface de démonstration accessible sans compte IBM. L’interface est fonctionnelle. Le résultat JSON de l’API est disponible. Par contre aucun surlignage n’est disponible et il faut chercher dans le résultat JSON les liens vers DBpedia pour les entités nommées ; cette information n’est pas affichée graphiquement. Un bug pour les rôles sémantiques : seule la première phrase est affichée graphiquement. Le résultat JSON est complet.
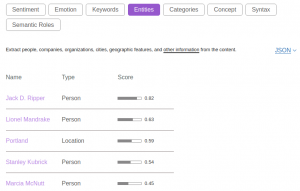
Nous arrivons à l’analyse du début (5000 caractères) de l’article de National Geographics, Why Do Many Reasonable People Doubt Science ? dans les 4 langues : anglais, français, espagnol, allemand. Le temps de traitement pour l’ensemble des traitements est rapide (2 secondes) quelle que soit la langue. La détection de langue fonctionne correctement. La catégorisation des entités nommées dépend de la version. Il y a actuellement 2 versions qui partagent différemment les classes habituelles (Personne, Lieu, Organisation, Date, Quantité…) en catégories et sous-catégories. Dans les 2 cas, la catégorisation compte environ 450 catégories ou sous-catégories. La catégorisation est donc potentiellement plus précise que les offres concurrentes. Nous analysons ensemble les entités nommées et les concepts, qui sont 2 fonctions séparées pour Natural Language Understanding. Les concepts n’ont pas de catégorie spécifique. Dans les 2 cas, entités et concepts, un score de pertinence par rapport au contenu et un lien vers DBpedia si disponible sont retournés. Il n’y a pas de score de fiabilité. En anglais, la détection des entités nommées et concepts est très bonne avec des URIs DBPedia souvent présentes (et correctes). J’ai relevé quelques erreurs : ‘rewards—but’ attribué à Lieu (peut-être problème de normalisation de caractère), ‘Frankenfood’ attribué à Lieu, ‘Apollo moon’ attribué à une Entité géographique. En français, on note une très bonne détection des concepts même si la liste est un peu courte (8 concepts). Les concepts ont leur URIs DBpedia et sont souvent pertinents (ex : ‘science’, ‘croyance’). Pour les entités, la détection est bonne mais uniquement 1 entité a un lien vers DBPedia (pour le lieu ‘France’). Il y a un bug dans la sortie JSON et l’affichage, les labels d’entités sont souvent tronqués. Ex : ‘Docteur Folamou’, ‘généra’, ‘américai’. Les types d’entités sont détectés correctement. Voici quelques erreurs de détection : ‘Apollo’ attribué à Personne, ‘:’ à Adresse IP, ‘Ebola’ à Organisation, ‘OGM’ à Organisation. En espagnol, la détection des entités nommées est un peu en-dessous de l’anglais mais reste très bonne. Les liens vers DBpedia sont présents. On remarque des caractères parasites dans l’affichage de la sortie JSON (peut-être un bug d’affichage seulement). Quelques erreurs : ‘Nnnn-no’ attribué à Personne, engaño (supercherie) attribué à État de santé. On détecte correctement les concepts avec leur URI DBpedia mais les concepts sont parfois des entités nommées et détectés aussi comme tel par Natural Language Understanding (ex : Estados Unidos (États-Unis), Stanley Kubrick). La liste des concepts proposés est courte. En allemand, les entités nommées contiennent beaucoup d’erreurs, et seule l’entité Nasa a une URI DBpedia. Les liens Internet vers DBPedia allemand ne fonctionnent pas au moment du test. Voici des exemples d’erreurs : ‘Stanley’ Lieu, ‘Zweifler’ (sceptiques) Entité géographique, ‘Komplott’ (complot) Personne, ‘Paranoia’ Personne, ‘Gene’ (gène) Personne, ‘einem’ (un) Mesure, ‘Forschungsergebnissen’ (résultats de recherche) Lieu. ‘Jack D. Ripper’ est séparés en 2 entités Personne. Les concepts détectés sont intéressants mais il n’y en a pas beaucoup.
En anglais, français et espagnol, l’extraction de mots-clés fournit une sélection de groupes nominaux corrects, classés par pertinence décroissante. Les résultats sont nombreux mais peuvent être filtrés par score pour ne conserver que les éléments les plus intéressants. En allemand, la liste de résultats ne contient quasiment que des noms simples et non des groupes nominaux. Les résultats ne sont parfois pas très pertinents. Ex : ‘Jahr’ (année), ‘Offizier’ (officier).
Natural Language Understanding renvoie un score de sentiment entre -1 (négatif) et 1 (positif) pour l’ensemble du contenu et pour des phrases précises du contenu. Natural Language Understanding peut aussi fournir des émotions en anglais. En anglais et en allemand, le contenu est jugé négatif avec des scores respectifs de -0.54 et -0.71. L’espagnol est plutôt négatif avec un score de -0.37 et le français est neutre (0.0).
L’analyseur syntaxique de Natural Language Understanding donne les unités lexicales, leur catégorie grammaticale et leur lemme. Natural Language Understanding fournit aussi des résultats appelés rôles sémantiques : il s’agit de triplets sujet, verbe et complément d’objet trouvés dans les phrases du contenu. Cela correspond à une partie d’un résultat de type dépendance syntaxique. En anglais, on note que l’analyseur syntaxique est trompé par la casse du titre ‘Why Do Many Reasonable People Doubt Science ?’ : ‘Do’, ‘Many’, … jusqu’à ‘Science’ sont catégorisés comme Nom Propre. Nous observons aussi quelques erreurs : ‘when’ est un Adverbe, ‘faces’ dans ‘faces opposition’ (fait face à une opposition) est un Nom, ‘gone’ est un Adjectif et ‘rogue’ est un Nom dans ‘who’s gone rogue’ (qui est devenu rebelle), ‘unspools’ dans ‘unspools his paranoid worldview’ (livre son vision paranoïaque du monde) est un Nom. Pour les rôles sémantiques, les résultats sont assez bons mais on note une mauvaise segmentation de phrase et une interprétation erronée dans ‘Strangelove in which Jack D. Ripper, an American general who’s gone rogue and ordered a nuclear attack on the Soviet Union, unspools his paranoid worldview (…)’ : le Sujet est ‘a nuclear attack’, le Verbe ‘order’ et le complément ‘on the Soviet Union’. Autre exemple : ‘Mandrake: Ah, yes, I have heard of that, Jack.’, le Sujet est ‘I’, le Verbe ‘have’ et le Complément ‘heard of that’. En français, l’analyse syntaxique et les rôles sémantiques ne sont pas disponibles. En espagnol, Natural Language Understanding fournit les rôles sémantiques mais pas l’analyse syntaxique. On note que la réponse JSON de l’API incorpore des caractères additionnels bizarres dans les phrases résultats ; il s’agit peut-être d’un problème d’affichage dans l’interface. Certains résultats sont clairement erronés. Par exemple ‘La era de la INCREDULIDAD’, le Sujet est ‘la’, le Verbe ‘era’ et le Complément ‘de la incredulidad’. Dabs ‘¿Por qué motivo personas razonables ponen en duda la razón?’, le Verbe est ‘qué’. En allemand, Natural Language Understanding fournit les rôles sémantiques mais pas l’analyse syntaxique. Là encore, on note des erreurs. Dans ‘Verschwörung Theorien verbreiten sich immer schneller’, le Sujet est ‘VerschwörungTheorien’, le Verbe est ‘verbreiten’ et le Complément ‘sich’. Ici on a plutôt affaire à un verbe pronominal. Dans
‘Mandrake: \”Äh, ja, doch, ich hab davon gehört, Jack.’, il n’y a pas de sujet, le Verbe est ‘gehört’, le Complément est ‘Jack’. Dans ‘Sollten wir uns Sorgen machen’, le Sujet est ‘Sorgen’, le Verbe ‘machen’ et le Complément ‘uns’.
Natural Language Understanding peut fournir une catégorisation de contenu selon un plan de classement propriétaire. En anglais, le contenu est classé en / health and fitness, / health and fitness / dental care, / health and fitness / disease. En français, le contenu est classé en
/ health and fitness / dental care, / law, govt and politics / politics, / health and fitness / disease. En espagnol le contenu est classé en / health and fitness / dental care, / law, govt and politics / politics, / food and drink. En allemand le contenu est classé dans / health and fitness / dental care, / food and drink. Comme pour la catégorisation de Google Cloud Natural Language, l’article de National Geographics parle de santé même s’il ne s’agit pas du fond de l’article qui est à propos de science et de croyance.
C’est offre la plus intéressante pour traiter des documents volumineux, ou même très volumineux. Par contre, dès qu’on souhaite l’adapter au spécifique métier, les coûts deviennent importants et nécessitent une vraie étude technico-financière.
Conclusion
Les différentes offres SaaS de langue naturelles testées proposent souvent des fonctionnalités similaires qui peuvent varier sur certains points. De manière générale, l’utilisation de ces services est facile : la documentation est suffisante, l’inscription au service est rapide et les APIs sont simples. La couverture en langue des différentes fonctionnalités est assez variable ainsi que le niveau de qualité. Dans les meilleurs cas, la qualité est très bonne et tout à fait adaptée à une utilisation industrielle.
Voici un résumé des offres présentées par fonctionnalité et langue :

Syntaxe simple : unité lexicale, catégorie grammaticale, lemme
Syntaxe avancée : dépendances syntaxiques ou rôles sémantiques
Voici un rappel des prix des 2 scénarios envisagés (réseaux sociaux ou documents A4) :

À fonctionnalités équivalentes, le premier facteur à prendre en compte pour choisir le service le plus économique est la nature du flux : la taille des documents, la fréquence d’appels et la possibilité d’optimiser les coûts par regroupement et/ou découpage. La différence peut être substantielle. Amazon et Google sont avantageux pour les documents courts et concis, alors que l’outil d’IBM semble avoir été conçu pour des documents plus volumineux.
Nous recommandons de bien évaluer les besoins de son projet en langue naturelle avant de se diriger vers l’une ou l’autre de ces offres. Un autre élément à considérer est l’intégration de ce service de langue naturelle à l’intérieur d’une offre de cloud computing plus vaste (virtualisation de serveurs, mais aussi services d’intelligence artificielle autres tels que catégorisation d’images, apprentissage automatique). De même certaines offres seulement proposent des analyses linguistiques personnalisées qui peuvent intéresser les utilisateurs avancés. Un autre élément important est la relative jeunesse de ces offres et l’évolution rapide en termes de mises à jour. Les résultats qualitatifs que nous obtenons aujourd’hui ne seront sûrement pas une image représentative de la qualité des différentes offres dans un futur proche et nous invitons les utilisateurs à vérifier par eux-mêmes les niveaux de maturité de chaque offre.