La désinformation est un sujet très en vogue, car elle est inhérente à la révolution de l’information. Les messages viraux des réseaux sociaux, les campagnes électorales, les publicités, voire même les nouvelles, constituent une liste non exhaustive de vecteurs infestés de fausses informations, publiées volontairement ou non.
Bien que les canulars diffusés par les réseaux sociaux puissent parfois faire sourire, l’actualité montre qu’ils représentent un risque majeur pour nos sociétés. À titre d’exemple, en 2016, un homme armé a attaqué une pizzeria aux Etats-Unis en raison d’une théorie conspirationniste diffusée sur les réseaux sociaux. Cette théorie mentionnait un réseau pédophile impliquant la fondation Clinton et une pizzeria nommée “Comet Ping Pong” qui en aurait été le centre [1].
Il existe d’ailleurs deux concepts couramment employés pour décrire les fausses informations : la désinformation et la mésinformation. À noter que leurs équivalents en anglais (disinformation et misinformation) ne traduisent pas nécessairement la nuance qu’on leur donne en français.
Quelques définitions
La mésinformation est communément perçue comme la diffusion d’informations partiales, incomplètes, ou fausses, et ceci involontairement ou pas. Mais ce concept est dans la majorité des cas employé pour décrire de l’information erronée relayée de façon non intentionnelle, principalement en raison de l’ignorance de l’auteur ou de son manque de rigueur.
La désinformation quant à elle implique aussi la diffusion d’informations erronées, mais de façon intentionnelle, avec l’objectif de faire adhérer à une cause et de convaincre, ou d’influer sur l’opinion publique.
Il s’agit donc de notions bien différentes même si le concept de désinformation est parfois perçu comme l’hyponyme de celui de mésinformation. On notera également que les définitions de ces deux concepts sont nombreuses et variées, et qu’elles continuent d’évoluer à mesure qu’ils font débat au sein de nos sociétés. Ce travail de définition a cependant fait clairement ressortir deux points fondamentaux sur lesquels s’appuyer : la nature de la source qui diffuse l’information et le degré de véracité des faits qu’elle contient. Ceci a ainsi été exploité pour établir un mécanisme d’évaluation de la nature des messages basé sur un score de véracité/honnêteté.
Approches existantes
Pour contribuer à la diminution de propagation de fausses informations, des équipes de journalistes se consacrent au fact-checking (vérification de faits), en analysant des articles de presse à travers différentes techniques. Ce fact-checking est en premier lieu effectué manuellement, ce qui prend beaucoup de temps. L’enjeu est d’outiller ces équipes en automatisant en partie cette vérification grâce à des outils informatiques.
Premièrement, l’utilisation du Traitement Automatique du Langage (TAL) est essentielle, pour pouvoir analyser sémantiquement les textes, en utilisant des marqueurs linguistiques.
Deuxièmement, des algorithmes de Machine Learning, Deep Learning et Transfer Learning sont mis en place et utilisés afin de classifier les textes, et aider dans la détection de fausses informations.
Enfin, des modèles probabilistes sont appliqués aux données, notamment grâce à l’analyse bayésienne de vérité. Avec tous ces outils, on peut aisément remarquer le potentiel de la sémantique et de l’IA dans l’amélioration de la compréhension homme-machine, ainsi que dans les performances informatiques.
Approche Mondeca
Nous avons pu mettre en place (*) une architecture de codes (voir figure). Ces codes ont d’abord permis de collecter des données brutes récupérées sur Internet. Ensuite, la structuration de ces données a été un point essentiel afin de pouvoir les analyser et les utiliser. Les données ont été représentées dans une base de connaissances sous le modèle RDF, modèle faisant partie de l’expansion du web sémantique. Enfin, l’utilisation de modèles de Machine Learning avec les données collectées a permis d’effectuer une première classification des données par rapport à la véracité des informations.
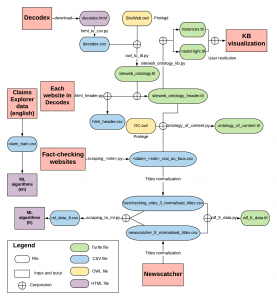
Comme il s’agit d’un domaine en fort développement mais pour lequel la majorité des connaissances reste à découvrir, les ressources (les données utiles par exemple) ne sont pas encore complètement adaptées. Ainsi, il est nécessaire de consacrer beaucoup de temps aux problèmes d’annotation ou de données périmées. À court terme, il paraît difficile de s’exempter totalement d’un travail fastidieux d’identification, mais il reste nécessaire d’être rigoureux dans l’annotation des données et l’amélioration des algorithmes de classification.
Perspectives
Ce travail devra se poursuivre afin de mettre en place une véritable aide aux équipes de fact-checking, et ainsi limiter le plus possible la propagation de fausses informations. C’est en tout cas une des missions du projet DIEKB , projet du dispositif RAPID, financé par la DGE et dont MONDECA en est coordinateur, de proposer des outils d’aide à la détection et cotation des messages désinformants avec des applications tant civiles que militaires.
Lauren PICARD
(*) Ce travail est le fruit de la coopération entre INSA Lyon et Mondeca pendant le stage de fin d’étude de Lauren Picard, 2020.
[1] Craig Silverman. How the bizarre conspiracy theory behind “pizzagate” was spread. Library Catalog : www.buzzfeed.com Section : CanadaNews.